Hive is a Data Warehouse model in Hadoop Eco-System. It can perform as an ETL tool on top of Hadoop. Enabling High Availability (HA) on Hive is not similar as we do in Master Services like Namenode and Resource Manager. Automatic failover will not happen in Hive (Hiveserver2). If any Hiveserver2 (HS2) fails, running jobs
How to Set Up High Availability for Resource Manager – Part 6
YARN is the Processing Layer of Hadoop, which consists of the Master (Resource Manager) and Slave (Node Manager) services to process the data. Resource Manager (RM) is the critical component that is responsible for resource allocation and management among all the jobs running in Hadoop Cluster. It is always recommended and best practice to have
How to Set Up High Availability for Namenode – Part 5
Hadoop has two core components which are HDFS and YARN. HDFS is for storing the Data, YARN is for processing the Data. HDFS is Hadoop Distributed File System, it has Namenode as Master Service and Datanode as Slave Service. Namenode is the critical component of Hadoop which is storing the metadata of data stored in

How to Install CDH and Configure Service Placements on CentOS/RHEL 7 – Part 4
In an earlier article, we have explained the installation of Cloudera Manager, in this article, you will learn how to install and configure CDH (Cloudera Distribution Hadoop) in RHEL/CentOS 7. While installing the CDH parcel, we have to ensure the Cloudera Manager and CDH compatibility. Cloudera version is having 3 parts – <major>.<minor>.<maintenance>. Cloudera Manager
How to Install and Configure Cloudera Manager on CentOS/RHEL 7 – Part 3
In this article, we described the step by step process to install Cloudera Manager as per industrial practices. In Part 2, we already have gone through the Cloudera Pre-requisites, make sure all the servers are prepared perfectly. Here we are going to have 5 node cluster where 2 masters and 3 workers. I have used
Setting Up Hadoop Pre-requisites and Security Hardening – Part 2
Hadoop Cluster Building is a step by step process where the process starts from purchasing the required servers, mounting into the rack, cabling, etc. and placing in Datacentre. Then we need to install the OS, it can be done using kickstart in the real-time environment if the cluster size is big. Once OS installed, then
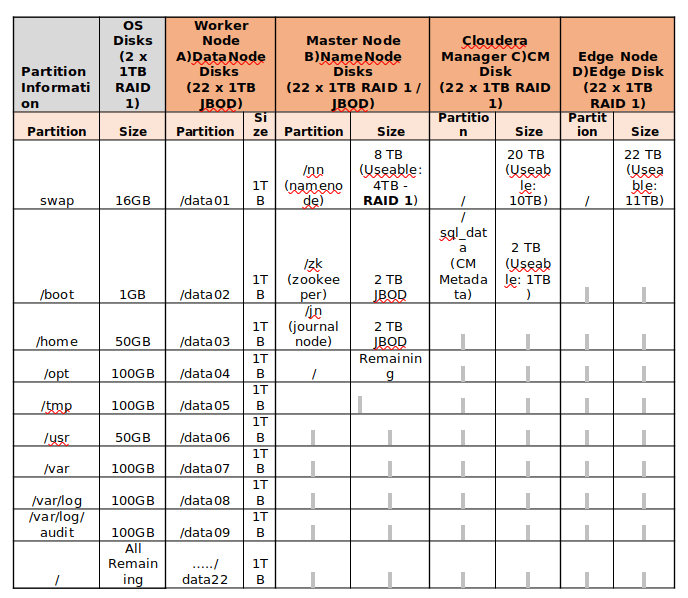
Best Practices for Deploying Hadoop Server on CentOS/RHEL 7 – Part 1
In this series of articles, we are going to cover the entire Cloudera Hadoop Cluster Building building with Vendor and Industrial recommended best practices. Part 1: Best Practices for Deploying Hadoop Server on CentOS/RHEL 7 Part 2: Setting Up Hadoop Pre-requisites and Security Hardening Part 3: How to Install and Configure the Cloudera Manager on
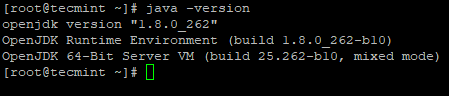
How to Install Hadoop Single Node Cluster (Pseudonode) on CentOS 7
Hadoop is an open-source framework that is widely used to deal with Bigdata. Most of the Bigdata/Data Analytics projects are being built up on top of the Hadoop Eco-System. It consists of two-layer, one is for Storing Data and another one is for Processing Data. Storage will be taken care of by its own filesystem